10 Ways to Reduce Reactive Maintenance
John Reeve, Total Resource Management
For purposes of this article, reactive maintenance is any planned or unplanned work with a priority designation of emergency or urgent, therefore requiring immediate attention. Plus, there could be work of any priority that is “worked on” outside of the weekly schedule, which this author calls “self-inflicted reactive maintenance.”
Problem Statement
Organizations that are predominantly reactive typically do not believe it is possible to perform work any other way. Overall, they are frustrated, which in turn impacts morale. Maybe it is a training issue or maybe it is a leadership issue. Either way, it is affecting worker productivity due to the majority of work being unplanned. Unscheduled work also affects job safety. When workers feel rushed to complete reactive maintenance, bad things happen. Lastly, those organizations with poor reliability typically waste 10 percent of their revenue.
10 Actions Worth Considering
This article provides 10 distinct actions you can take to become more proactive. As you will see, the asset management system (AMS) plays a major role. Typically, users struggle to leverage the AMS in support of asset reliability, but the reason for this simply may be because you need a more encompassing set of instructions. So, here they are.
- Establish a solid preventive maintenance (PM) and/or predictive maintenance (PdM) program. Where possible, establish maintenance strategies using formal reliability centered maintenance (RCM) analysis. Otherwise, rely on manuals from the original equipment manufacturer (OEM) and staff experience. Place emphasis on condition monitoring technologies, such as PdM, which makes it easier to recognize defects. With early identification, the staff can prevent unplanned breakdowns and collateral damage. By proactively planning needed repairs, the organization saves cost. In support of your PM/PdM program, you should ensure that some maintenance staff members have certifications in PdM technologies (e.g., vibration, ultrasound, infrared, tribology), as well as knowledge in precision maintenance skills.Tip: Link PM/PdM to failure modes and store this relationship inside the AMS in the failure mode and effects analysis (FMEA) register where they are easily referenced.
- Establish a reliability team. It helps to have more than one person focused on asset reliability and plant availability. This group would rely heavily on the AMS system for failure analysis, as well as decisions pertaining to root cause analysis, RCM and localized FMEA.
- Perform root cause analysis (RCA) on worst events to identify the true cause based on the trigger point.
- Perform a localized FMEA where needed, for instance to evaluate a specific system or asset to isolate a problem and validate failure modes by comparing AMS failure history (failure modes) to the FMEA register.
- Utilize defect elimination techniques, such as brainstorming, quality circles and kaizen events, all of which involve working level and cross-functional groups. Conduct system walk-downs and record problems as a group. Summarize findings and propose solutions.
- Establish a core team to manage the complete AMS system. Train the staff, establish business rules, build standard operating procedures (SOPs), set up mandatory fields and choice lists, run error checks, survey the users for problems and conduct periodic audits. Most importantly, set up the AMS with the endgame in mind (e.g., failure analysis). The core team should maintain a five-year plan for direction/guidance in support of operational excellence.
- Perform formal job planning to provide sequenced steps, material/craft requirements, safety/hazard precautions, as well as reference materials and permits. This is being “fully planned.” Job instructions help keep workers safe, organized and informed. Job plans also help the craft follow standardized actions to ensure asset performance. The planner role is multifaceted, but key points include a job plan library, backlog management, foundation data accuracy and a maintenance of asset-to-spares library.
- Create a formal weekly schedule process by selecting the fully planned work that can be relied on by operations, maintenance, warehouse/purchasing, and health, safety and the environment (HSE). Some schedulers also attempt to bundle like work from the backlog, or they may perform plant system window scheduling. Tip: If the organization is mostly reactive, it may be good to create a reactive maintenance team and let the others focus on proactive work. Oddly enough, this action will help management emphasize the weekly schedule with “no excuses not to perform.” Lastly, train maintenance to not perform self-inflicted reactive maintenance whereby they purposely decide to do unscheduled, low priority work.
- Trend percent reactive to manage reactive work. Be sure you can extract reactive maintenance using structured query language (SQL). This can be an important metric for trending and comparison. Reactive work is usually Priority 1 (emergency), Priority 2 (urgent) and any other work order that breaks into the schedule. Otherwise, if you are repairing an asset, such as a condition based maintenance discovery, you should have time to properly plan and schedule this work. Therefore, it is not reactive.
- Capture good failure data, specifically failure modes. Use this failure data in failure analysis (e.g., asset offender report) to determine worst offenders. Properly stored failure data (e.g., validated fields) can reduce failure analysis time by up to 90 percent if it is actionable (e.g., retrievable via SQL) as opposed to pure text. Inaccurate/incomplete data, however, can severely limit the ability to extract meaningful reports (e.g., failure analytics). By combining the failed component, component problem and cause code, you can create the failure mode that is used to identify optimum maintenance strategy.Tip: Failure data should also include work order feedback (e.g., suggestions from the maintenance technicians), such as issues pertaining to ergonomics, maintainability, safety and design flaws.
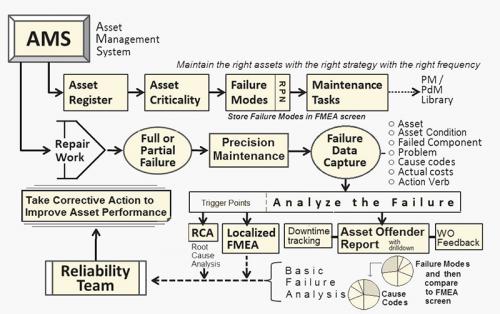
Precision Maintenance Needs Precision Data
In Figure 2, you see an ideal design for setting up an AMS with emphasis on failure analysis. Also note the unique design for building the failure mode, which is the combination of (1) failed component, (2) component problem and (3) possibly the cause code, depending on how you stored this data in the FMEA register. Other key elements of this process include the trigger points for RCA, work order feedback, a reliability team and the asset offender report, such as the mean time between failures (MTBF) analytic. With the asset offender report, you can focus on“bad actors” and manage by exception.
According to RCM expert Jack Nicholas, “The single most important thing to assure reliability is to rely on procedures, staff feedback with follow-up and reinforcement. Good procedures help ensure precision.”
Work order feedback can capture suggestions for improvement. Although not shown in Figure 2’s diagram, there also needs to be process audits, data error checks and business analyst (working level) surveys.
Can you Reduce Reactive Maintenance?
Reducing reactive maintenance is not an impossible task. The trick, however, is to start small. Perhaps you’ll focus on the critical assets first. The AMS software may need to be configured and training will be required. Asset reliability and job safety is everyone’s job. All that is needed is a roadmap to get there.

John Reeve
John Reeve is the Senior Business Consultant at Total Resource Management. Mr. Reeve is a seasoned professional and consultant with over 25 years of diverse industry experience, with expertise in work, asset and reliability management system design. Mr. Reeve obtained a United States Patent for maintenance scheduling.
Related Articles

The Journey to Operational Excellence

Growing Old: 6 Risks of Aging Facilities

Did you Review Your Last Shutdown/Turnaround?

Destratification Fans: A Solution for Temperature Stratification in Industrial Spaces

Using Performance and Development to Sustain Performance Improvement

Mastering Lean: Balancing Detail and Business Strategy


