Reliability: Concepts and Trends
The most known concept to define reliability is: “Probability that an asset or system operates without failing during a given period of time under some operation conditions previously established.”
Sometimes, this concept is wrongly used due to the particular use given to the word failure. For many, failure only means shutdowns, so they construct complex mathematical formulas to calculate shutdown probability without taking into account that a failure also occurs when being inefficient, insecure and costly, having a high rejection level, or contributing to a bad image.
Other factors to be taken into account are shutdown causes that may occur for numerous reasons, so comparing apples and oranges, as the expression goes, should be avoided. An example is comparing shutdowns due to bearing lubrication with shutdowns due to errors in bearing mountings. It is not the same changing an item because it is going to fail versus changing it because it failed versus changing it because a frequency was met before it failed. Specifying an item that failed due to wearing is not the same as another that failed due to an improper installation or one damaged by an accident.
Is It a Statistic Issue?
A common discussion is whether or not reliability is a statistic issue. Managing data has an undeniable usefulness in the company’s management and direction. It is necessary to distinguish if statistics are used to manage real data to see its behavior or to support forecasts and estimations that sometimes border on daring and irresponsible speculations.
Some authors adhere to defining mathematical postulates as an absolute truth about failures and deny the fact that numbers of analyzed failures mix effects with causes. In addition, they deny that having failure data to analyze is accepting that failures occur and with more data come more failures.
The most common misconception of reliability is that it is like the average time between failure occurrences. This statement has several connotations to consider. The first is to remember that the cipher is an average and the failure concept is associated with more shutdowns than with unconformities, such as spilling, a nonconforming product, or increased risks, which are failures too.
Datum as such, is an average cipher. There’s a big difference between probability and reality, thus generating confusion. A probable failure is a possible failure and an occurred failure is a real failure, but a calculus logarithm doesn’t necessarily assure its occurrence at a given point.
Therefore, using calculated, desired, estimated, arbitrarily fixed, imagined, recommended by manuals and even invented ciphers may carry error percentages, inaccuracies and deficiencies requiring responsible handling.
For example, Figure 1 shows the various failure causes of a boiler.
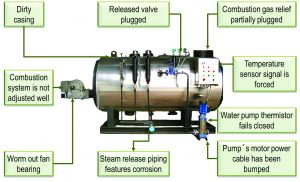
If failures are analyzed, Figure 2 shows the various results.
It is clear that not all failures affect availability, therefore, they should not be used in calculating mean time between failures (MTBF) as it is repeatedly done.
Getting back to boiler failures:
- Assume that 10 failure modes are produced within 720 hours (one month).
- Only two of the failure causes listed in Figure 2 produce a shutdown, generating a total of 20 shutdown hours.
- According to the traditional failure concept, the calculation of MTBF for the boiler would be: MTBF = (720 hours – 20 hours) / 2 failures = 350 hours.
- If the company’s MTBF goal is 300 hours, the goal would be met.
- The probability that the boiler does not fail before the MTBF goal would be calculated this way: e-(300/350) = 42.5 percent.
Thus, analyzing numbers may only give peace of mind to some people since there are other reasons an asset may fail, such as:
- Non-compliance of cleaning standards;
- Inoperative protections;
- Harmful situations for security and the environment;
- Greater fuel consumption, which is a greater cost.If the asset does not perform all required functions as desired, it is also considered a failure.
Therefore, if the real failure concept is applied, calculations would be different:
- MTBF = 720 hours – 20 hours / 10 failures = 70 hours.
- Since the company’s MTBF is 300 hours, the purpose would not be met.
- With the current failure concept, the probability that the boiler does not fail before the MTBF goal would be calculated this way: Probability = e-(70/350) = 1.37 percent.Very few companies have data on MTBF; what they really have is datum on mean time between shutdowns.
Very few companies record failure occurrence using the failure mode scope and those that do, their information systems make the MTBF calculation difficult.
So, what’s the solution? The time being used for mathematical calculation of MTBF or failure probability would be better spent defining failure consequences and devising an action plan to mitigate those consequences.
How to Improve Reliability
Currently, the issue facing maintenance staff is not only learning what the new techniques are, but also being able to decide which ones are useful for their companies.
If properly chosen and used in an integrated manner, maintenance practices and outputs will likely improve. Likewise, costs will be optimized. If improperly chosen, more problems will be created which, in turn, will worsen existing ones.
Some companies have gone beyond statistics and have reviewed their internal practices, carrying out benchmarking with those that are outstanding. These organizations came to the conclusion that it is impossible to talk about reliability as a unique cipher. Therefore, it is necessary to use several measurements as fundamental indicators of inputs/outputs of the processes.
The need for reliability in installations is as old as humanity, but undeniably, the growing relevance of environmental issues and their security have led to the need of changing orientation of some markets and niches due to:
- More complex products.
- Greater pressure to reduce costs to be more competitive.
- A greater number of operational functions carried out by equipment and machines.
- Requirements to reduce products’ weight and volume, and maintaining and improving performance and security standards.
- Requirements to increase or reduce operation duration of products to increase or reduce demand.
- Greater difficulties to carry out maintenance interventions due to asset utilization increases.
- Trends to use software, electronic, pneumatic, or hydraulic components having different wearing behavior in response to components failing in function of age.
- Current legislation that is increasingly more demanding and less tolerant.
- Greater impact of shutdowns and operational losses on sales and products.
- Growing demands for quality in services and products.
- New perceptions of a company’s image or commitment.
- Commitments to reduce the human life loss risk.
- Requests to reduce the spilling risk or affectations of the equipment on the environment.
These new demands drive the use of strategies that have been successfully applied in many companies, strengthening global performance, optimizing costs, reducing risks, improving corporate image, lowering environmental impact and consolidating business results.
Successful companies have made a concerted effort to incorporate their maintenance improvement strategies into other corporate initiatives, avoiding or preventing the syndrome of the campaign of the moment, peak of the wave, or the promotion of the month. The best indication that this effort produces satisfaction is when it turns into a durable and stable policy.
Among the most successful tools being used consistently are:
- Reliability as a global concept instead of reducing costs or downtime.
- Carrying out diagnoses, audits and evaluations of maintenance practices.
- A development strategic plan describing and establishing a corporate vision related to reliability and asset good performance.
- Extensive utilization of performance measurements with appropriate goals.
- Benchmarking to identify opportunities and barriers for improvement.
- Sharing knowledge and achieving consensus among areas typically separated; using teams with different functions and specialties who work together during a specific period of time to analyze problems and opportunities aimed at a common output.
Conclusion
To achieve reliability, maintenance is not the only responsible area. It requires responsible designs, consistent and trained operators, professional purchasers and stable policies. In other words, several responsible actors take part during an asset’s lifecycle.
Maintenance is considered an action; it is more of a joint responsibility than a function. Maintenance starts with selecting equipment and follows with installation. It is supported by the right operation and good maintenance, with support provided by purchases and inventories.
Those responsible for whether assets will be reliable or not are: design; selection; manufacturing; suppliers; installation; environment; operation; maintenance; stores; and purchases.
As you can see, improving MTBF is not enough.

Carlos Mario Perez Jaramillo
Carlos Mario Perez Jaramillo is a Mechanical Engineer and Information Systems Specialist for Soporte y Cía. Mr. Perez is a specialist in asset management and project management and has worked in dissemination, training and application of RCM2.
Related Articles

Some Plain Talk About Nuts and Bolts: Part 1 of 2

The Full Circle of Engineering Education

Design for Maintainability: The Innovation Process in Long Term Engineering Projects
Energy Optimization

The Meaning of Bearing Life
Preheater Points Out the Value of Cooling Off


