Reliability, Resilience and Damage
Malcolm Hide
Reliability and Resilience
Research currently being carried out by the Center for Risk and Reliability, University of Maryland 1, and funded by the U.S. Navy is aimed at quantifying reliability in scientific terms. The present study “relies on a science-based explanation of damage as the source of material failure and develops an alternative approach to reliability assessment based on the second law of thermodynamics.” Current reliability calculations are predisposed to a single failure mode or mechanism and assume a constant failure rate, while this research implies that reliability is a function of the level of damage a system can sustain, with the operational environment, operating conditions and operational envelope determining the rate of damage growth.
This article explores the areas where significant levels of damage can be controlled in order to improve system reliability.
In effect, the Center for Risk and Reliability study is looking at how the dissipation in entropy can be equated to the level of damage in a system and as the damage grows, increases the likelihood of failure which, in effect, reduces the reliability.
Reliability in an engineering context is the ability of an item to perform a required function under given conditions for a given time interval. It is generally assumed that the item is in a state to perform this required function at the beginning of the time interval and reliability performance is usually expressed as a probability. For example, an electrical relay has a 99 percent probability that it will achieve 100,000 operating cycles at full load.
Taking this a step further using the example of the relay, based on the operational environment (no impact), operating conditions (full load switching) and operational envelope (four cycles per minute, 24/7/365), the level of damage growth over time can be calculated to predict an individual mean time between failures (MTBF) for this component of 17.4 days with a 99 percent accuracy.
Since current reliability calculations are predisposed to a single failure mode or mechanism and assume a constant failure rate, for the relay example, this might be arc damage on the contacts, but spring failure or coil overheat also could be possible. The problem is that for every component, there will be several failure modes or mechanisms and each of these would generate its own failure predictions, resulting in an incoherent reliability calculation. The entropy based failure prediction, on the other hand, takes all these elements into consideration to determine a level of damage, which is then used to calculate the life of the component.
Reliability, therefore, becomes a function of the level of damage a system can sustain (i.e., resilience), with the operational environment, operating conditions and operational envelope determining the rate of damage growth.
Reliability (R) ≡ Resiliance (X) − Damage (D)
Creating Resilience
Numerous satellites have been operational for many years without any human intervention. This is an indication that resilience is a function of the creation of the equipment or system and not necessarily driven by human intervention. Take the relay example and select one with an average life of 5,000 cycles and use it in the same application. Ultimately, you have built in a failure mode with an MTBF of 0.86 days. Clearly, this would be an inherently unreliable system based on the component’s failure because the level of attention and repair required is excessive.
In order to improve the reliability of the system, therefore, a design review is necessary. If, instead, you select a relay that has an average life of 200,000 cycles, the MTBF increases to 34.7 days, which although still unreliable, is much improved than the first option. Fundamentally though, this design is flawed as the duty cycle on the relay is excessive and in order to improve the resilience of the system, a design change was needed. Other ways of doing this would be to reduce the number of activations, alternating the activations between multiple relays or eliminating the requirement for the activations.
Once the design is completed, the resilience creation moves into a new phase where the design is implemented. Unfortunately, this is where you start eroding the resilience, as opposed to enhancing it. This is caused by several factors:
- Material selection differs from the material specified during the design phase – Invariably, this is driven by price with some form of value engineering. Quite often, the reasoning behind the designer’s decisions or selection of components is forgotten or ignored and, as a result, the components no longer meet the design requirements. Taking the relay example, the best priced option could well be the unit with an average life of 5,000 activations as opposed to the one with 200,000 activations. There is nothing wrong with value engineering as long as it does not corrupt the design intent.
- Defective materials as a result of manufacturing defects – Manufacturing defects should be picked up during quality control inspections throughout the manufacturing process. However, some manufacturing defects could be so deep rooted in the component that it would be virtually impossible to detect; and the level of detection gets reflected in the price. These usually result in early component failures or shortened life expectancy of individual components and could easily result in extensive rework to replace the defective components.
- Defective materials due to a lack of care during the delivery process – Delivery process covers everything from the handling of the component at the manufacturer to the transportation, storage and finally the handling of the component on the installation site. Managing the level of care during this process is very difficult, since shock, vibration, environment and storage conditions need to be considered. Lapses in these controls usually result in early component failures or shortened life expectancy of individual components, similar to those resulting from manufacturing defects.
- Improper or poor installation of components or equipment – Experience shows that an incorrectly installed bearing or electronic components installed without the correct electrostatic discharge (ESD) protection can both result in a shortened life expectancy due to the damage caused to the component. The future reliability of the system is dependent on the level of care applied during the installation, not only in terms of the method of installation, but also in the diligence during the installation. Examples of this would be poor wiring connections resulting in connector failures or incorrect equipment setup resulting in excessive wear. Invariably, these are usually a result of poor management of the installation contractors and a poorly executed installation test procedure prior to the equipment or system being brought into operation.
- Live testing carried out during the commissioning phase – Commissioning should be a series of progressive tests that prove the system meets the design parameters. However, some tests used to prove the safety of the system could be quite damaging in order to ensure the system can protect itself adequately. Consider the impact on a compressor in full load conditions when the emergency stop button is pressed. In addition to this level of testing, consider also the length of time it takes to commission a fairly large site with thousands of interlinked pieces of equipment. In some cases, such as a construction environment, this could be years, with significant environmental conditions that do not reflect the normal operating conditions.
Once the system is ready to go into operation, many of the components already have incurred a level of damage, which ultimately reduces the level of damage the system can sustain, thus impacting system reliability. Expressing it as a mathematical formula:
Xd = Xdes – (Dms + Dman + Ddel + Dinst + Dcomm)
| Where: | |
|---|---|
| Xd = | Delivered Resilience |
| Xdes = | Design Resilience |
| Dms = | Damage from Material Selection |
| Dman = | Manufacturing Damage |
| Ddel = | Delivery Damage |
| Dinst = | Installation Damage |
| Dcomm = | Commissioning Damage |
This is the level of resilience that is delivered when new equipment or a new system is installed.
Improving Resilience
Taking the installation resilience as a point in time, you need to stabilize the operation and eliminate potential damage caused by poor installation. One of the key areas of focus should be reviewing control elements, especially in relation to software related updates. Typically, a system beds itself in and when these actions are taken, the system will become more resilient (Figure 1).
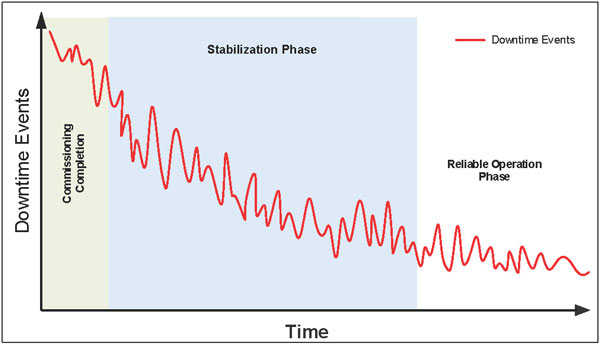
Stabilization of the operation and software and timing updates are not covered in this article, but there are several systems available that can assist in identifying areas where these improvements could make the most impact on the duration of the stabilization phase. However, from an installation damage perspective, you should consider these condition monitoring activities to identify potential issues that can be remedied.
- Infrared thermography to identify equipment that may be heading into trouble in terms of hot spots and upward trends in overall temperature. Infrared thermography works well on electrical motors, electrical connections over 50v, heat loss or cold areas and failing bearings.
- Vibration monitoring to identify unusual vibration signatures and levels, as well as rising trends in vibration. Vibration monitoring is good for most rotating equipment, however, it is poor at slow rotating equipment, so it will be an issue to identify problems with transient vibration caused by equipment that stops and starts frequently. On the run-up and run-down of rotating equipment, vibration monitoring will highlight any harmonic related issues that might also cause damage if it is not properly managed.
- Ultrasound to help identify leaks and other unusually high energy noise, such as that found on pneumatics, bearings and electrical arcing.
- Oil analysis, where there is an adequate volume of oil to support it, could be used to identify systems where there is excessive wear being generated, such as white metal bearings, gear trains, or hydraulic systems.
All of these, as well as other condition monitoring activities, would give you a heads up on the developing level of damage that could be averted if addressed early enough. This allows you to schedule the repairs in a timely manner to ensure the resilience of the new system can be raised to the highest possible level when the system is handed over for normal operational use.
Maintaining Resilience
Once a system goes into full production, the true art of reliability is to keep the system running at the correct efficiency and quality output with minimal intervention. In order to do so, you need to put processes in place to monitor and limit the growth in damage, which ultimately erodes the resilience of the system. Expressing this as a mathematical formula:
Xt = Xd − Dlife
| Where: | |
|---|---|
| Xt = | Aged Resilience |
| Xd = | Delivered Resilience |
| Dlife = | Damage Caused by Operational Life |
And Dlife is directly proportional to these elements:
- The level of care applied to the system: You know that if you take care of the equipment, identify failures and take corrective action prior to them failing, the equipment or system tends to retain its reliability longer because you don’t allow it to suffer from secondary failures. Take a gland that comes loose on an electrical panel as an example. When you see it is loose, you tighten it, thus reducing the risk of ingress of moisture in the panel and limiting the likelihood of corroded connectors.
- The level of maintenance performed on the system: You know from experience that if you only apply breakdown maintenance on equipment or a system, the frequency of failures will escalate to an unsustainable level. At this point, you would be running from one breakdown to the next, almost making it impossible to set a preventive maintenance (PM) program in place. Alternatively, you could be over maintaining items to the extent that you are taking systems off-line for unnecessary inspections purely on the off chance you might find some hidden failure that might be lurking.
- Human error and poor workmanship: When components are replaced or you perform any invasive inspection (i.e., you go beyond the level of removing safety guards and start dismantling equipment to perform an inspection), you introduce the potential for human error. Some estimates are that between 50 and 70 percent of equipment failures are a result of human error. This may be a result of incorrect methodology used to replace the part or reassemble the equipment, lack of training or skill required for the task, or errors caused by bad practice or poor workmanship.
- Replacement parts must conform to design requirements: When replacement parts are purchased, they need to conform to the system’s design parameters, otherwise you have the potential of changing the resilience of the system, similar to the relay selection in the earlier example. Furthermore, a system may be designed in a way that a particular failure is built in to protect the rest of the system from significant damage. If you change the failing part with one that is more robust, you have, in effect, changed the design parameters. As a result, you may have moved the failure to another component, which could be far more catastrophic. Procurement processes and component specifications should avoid this possibility.
- Quick fixes that are not correctly managed: When the equipment or system is running and a failure occurs, you are forced to apply a quick fix to get the system running to meet the demand. If you don’t go back and do a permanent repair and continue to run with the quick fix in place, the cause of the original failure is still present and the level of damage is potentially increasing. This is a cultural issue that is fostered when the maintenance crew is rewarded for its rapid response to issues and not for long-term system improvements.
- Using the equipment or system outside of the designed parameters: The equipment or system was designed to perform in a specific manner and as long as it is used in that manner, it will usually perform reliably. But if you change the operational processes and do not change the design’s intent, the system or equipment may become less reliable and far less efficient.
- Residual equipment life: Using the relay example, if the relay selected provides an MTBF of 15.4 days (100,000 cycles) with an accuracy of 99 percent, on day one of the relay’s life, you have almost a 100 percent likelihood of a failure-free day. But on day 16, you would have nearly a 100 percent likelihood of a failure. The same applies to a system; as time progresses, the level of damage on the components will grow to a point where aged resilience is significantly reduced. As a result, the system’s reliability is significantly lowered.
It is clear from the list of elements that many are within the power of the operators and maintainers to manage and control, while the residual equipment life is more a function of design.
Conclusion
Reliability is a function of the level of damage inflicted on the system and, therefore, should equate to X t at a point in time, as shown in the Figure 2 graph.
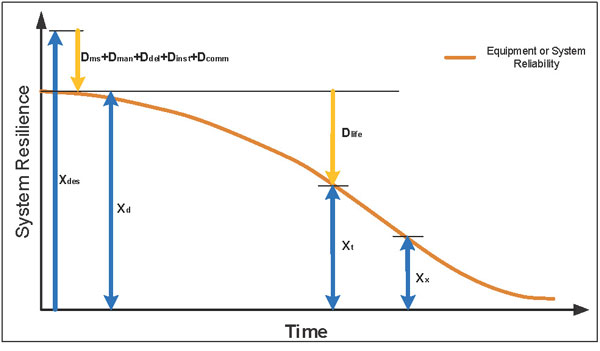
At a point in time (Xx), when the resilience of the equipment or system is less than what is necessary to retain the level of reliability that is expected, the system becomes inherently unreliable. Once the equipment or system has reached this point, experience shows that very little can be done to rebuild the level of resilience to support the required reliability. The cost of maintenance at this point starts escalating, as more manpower is required to resolve the number of faults. Also, as the number of faults increase, so do the number of component replacements. Equipment or system availability at this point becomes more of a function of manpower and MTTR than system reliability.
Organizations need to change their perspective on the role of maintainers. As this article shows, maintainers need to be focused on minimizing damage to the equipment or system, as this ultimately improves the level of reliability as time progresses. In addition, organizations should look to find ways to quantify the elements within their control in order to predict the level of resilience at any point in time.
References

Malcolm Hide
Malcolm Hide is an independent maintenance consultant and has over 35 years of experience in maintenance and design. He has worked in the steel, oil & gas and food processing industries, and due to this broad range of experience, Malcolm has been able to apply his knowledge of asset management and maintenance requirements to many environments and applications. Currently he is a Managing Director at Strategic Maintenance Limited.
Related Articles

Why do maintenance improvement initiatives fail to deliver? (Hedgehog or Fox?)

The Evolution of Performance Measurement


Practical Maintenance Strategy Design For Capital Expansions

The New Productivity Challenge



