One of the concerns clients have when they go to the cloud is the degree of access they have to the underlying infrastructure to control and generally administrate their MAS instances. The Tools API provides a few of the commonly needed actions an Administrator would need to perform, without them having to ask for permission. The ability for you to make the connection and requests is contingent upon the nature of your cloud hosting agreement and provider. Start by asking this question before trying to set up and make the connection on your own.
For full disclosure, much of the detail for this article can be found from IBM here.
However, indulge us a bit as we walk through what the Tools API brings to you as a MAS client, whether your instances are on-prem or being hosted in the cloud by someone.
What is the Tools API?
Starting way back with Manage 8.1, the Tools API provides many of the Cloud Command Line Interface (CLI) tools that a client could execute on their instances which are hosted in the cloud. As a side note, Manage is now at release 8.6 under the MAS 8.10 umbrella.
Commands such as running the Integrity Checker, starting/stopping Manage pods, uploading logs, etc. are all common operations that an Administrative User might wish to perform. Depending upon your hosting situation, your host may require you to submit a request to execute these commands, or they may give you access to do on your own. Best to check your hosting agreement before you try to set up what the IBM URL suggests.
Setup
The first thing you are going to need to do is download a REST command/request application such as Postman or the like. These applications enable you to connect to servers (via URLs) and execute REST requests such as POST, GET, etc. You can form, execute, and then save your requests, so once you have your key functions in place, you simply execute the requests as needed. Tools such as Postman have many useful functions when it comes to interacting with APIs.
The URL provided by IBM points to the need to configure the Logging app within Manage to provide the necessary application access to the User(s) you expect to execute the Tools commands. We strongly recommend that the list of Users granted this degree of access is very small and are Administration level Users.
You will also need to generate an API Key for the Postman app to use to authenticate with the server when it attempts to make a connection. This is done via the API Key application under the Integrations module of Manage. It is a simple matter to generate the key for a particular User (most likely MAXADMIN) and copy it for use later.
Making the connection
Armed with Postman and your API Key, you can configure your first REST request. As a side note, you are making these requests to the maxinst pod that is running under the Red Hat OpenShift environment that is supporting your MAS instance. This detail may be important if you must work with your hosting provider to gain access.
You will need to know the hosting details to form proper URLs to execute your REST requests. This can be frustrating because the URL must be exact. A sample REST request URL would look like:
Note that the “host:port” section of the URL is very specific to the instance you are attempting to connect to.
Executing Requests
Now comes the fun part… executing REST requests. If you are new to applications like Postman, there will be a small learning curve to understand how it works, and then some learning to understand the results that the CLI tools return to you.
Leverage the IBM link to walk through each of the Tools to get a feel for what they do for you.
… do just that. They stop the Manage pod! If you just did this in your Production instance, your phone would certainly start ringing. Best to learn on your non-production instances before moving over to the ones your business depends upon. Use the managestart request to restart the pod if you make this error.
One function that is nice to have is the ability to capture logs and then access them for analysis without having to ask for them or enter tickets to the host. When the submit upload log request is made, all the Manage Liberty (the underlying MAS application server that replaced WebSphere) pod logs are zipped up and uploaded to the underlying cloud object storage. The logs of the cron, UI, MIF, and RPT pods are included all at once.
Of course, you will need to have access to this storage location to retrieve the zipped files. More discussions with your Cloud host for sure.
Wrap up
TRM, being a cloud host, fields requests for this degree of system access on a very regular basis. We certainly help our clients achieve the access they need to manage their instances. Some need access, while others are perfectly happy having us do all the work!
John Q. Todd
John Q. Todd has nearly 30 years of business and technical experience in the Project Management, Process development/improvement, Quality/ISO/CMMI Management, Technical Training, Reliability Engineering, Maintenance, Application development, Risk Management, & Enterprise Asset Management fields. His experience includes work as a Reliability Engineer & RCM implementer for NASA/JPL Deep Space Network, as well as numerous customer projects and consulting activities as a reliability and spares analysis expert. He is a Sr. Business Consultant and Product Researcher with Total Resource Management, an an IBM Gold Business Partner – focused on the market-leading EAM solution, Maximo, specializes in improving asset and operational performance by delivering strategic consulting services with world class functional and technical expertise.
Expert troubleshooters have a good understanding of the operation of electrical components that are used in circuits they are familiar with, and even ones they are not. They use a system or approach that allows them to logically and systematically analyze a circuit and determine exactly what is wrong. They also understand and effectively use tools such as prints, diagrams and test instruments to identify defective components. Finally, they have had the opportunity to develop and refine their troubleshooting skills.
Expert troubleshooters have a good understanding of the operation of electrical components that are used in circuits they are familiar with, and even ones they are not. They use a system or approach that allows them to logically and systematically analyze a circuit and determine exactly what is wrong. They also understand and effectively use tools such as prints, diagrams and test instruments to identify defective components. Finally, they have had the opportunity to develop and refine their troubleshooting skills.
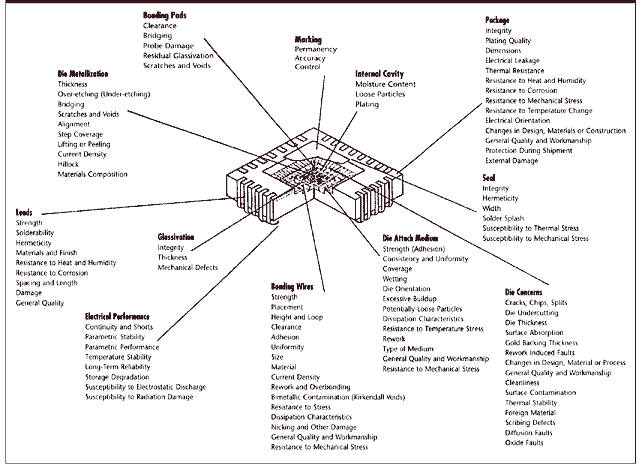
Semiconductor devices are almost always part of a larger, more complex piece of electronic equipment. These devices operate in concert with other circuit elements and are subject to system, subsystem and environmental influences. When equipment fails in the field or on the shop floor, technicians usually begin their evaluations with the unit's smallest, most easily replaceable module or subsystem. The subsystem is then sent to a lab, where technicians troubleshoot the problem to an individual component, which is then removed--often with less-than-controlled thermal, mechanical and electrical stresses--and submitted to a laboratory for analysis. Although this isn't the optimal failure analysis path, it is generally what actually happens.
Semiconductor devices are almost always part of a larger, more complex piece of electronic equipment. These devices operate in concert with other circuit elements and are subject to system, subsystem and environmental influences. When equipment fails in the field or on the shop floor, technicians usually begin their evaluations with the unit's smallest, most easily replaceable module or subsystem. The subsystem is then sent to a lab, where technicians troubleshoot the problem to an individual component, which is then removed--often with less-than-controlled thermal, mechanical and electrical stresses--and submitted to a laboratory for analysis. Although this isn't the optimal failure analysis path, it is generally what actually happens.
In an ideal world, multiple components could be produced in a single piece, or coupled and installed in perfect alignment. However, in the real world, separate components must be brought together and connected onsite. Couplings are required to transmit rotational forces (torque) between two lengths of shaft, and despite the most rigorous attempts, alignment is never perfect. To maximize the life of components such as bearings and shafts, flexibility must be built in to absorb the residual misalignment that remains after all possible adjustments are made. Proper lubrication of couplings is critical to their performance.
In an ideal world, multiple components could be produced in a single piece, or coupled and installed in perfect alignment. However, in the real world, separate components must be brought together and connected onsite. Couplings are required to transmit rotational forces (torque) between two lengths of shaft, and despite the most rigorous attempts, alignment is never perfect. To maximize the life of components such as bearings and shafts, flexibility must be built in to absorb the residual misalignment that remains after all possible adjustments are made. Proper lubrication of couplings is critical to their performance.
The key to realizing greater savings from more informed management decisions is to predetermine the "True" cost of downtime for each profit center category. True downtime cost is a methodology of analyzing all cost factors associated with downtime, and using this information for cost justification and day to day management decisions. Most likely, this data is already being collected in your facility, and need only be consolidated and organized according to the true downtime cost guidelines.
The key to realizing greater savings from more informed management decisions is to predetermine the "True" cost of downtime for each profit center category. True downtime cost is a methodology of analyzing all cost factors associated with downtime, and using this information for cost justification and day to day management decisions. Most likely, this data is already being collected in your facility, and need only be consolidated and organized according to the true downtime cost guidelines.
I use the term RCPE because it is a waste of good initiatives and time to only find the root cause of a problem, but not fixing it. I like to use the word problem; a more common terminology is Root Cause Failure Analysis (RCFA), instead of failure because the word failure often leads to a focus on equipment and maintenance. The word problem includes all operational, quality, speed, high costs and other losses. To eliminate problems is a joint responsibility between operations, maintenance and engineering.
I use the term RCPE because it is a waste of good initiatives and time to only find the root cause of a problem, but not fixing it. I like to use the word problem; a more common terminology is Root Cause Failure Analysis (RCFA), instead of failure because the word failure often leads to a focus on equipment and maintenance. The word problem includes all operational, quality, speed, high costs and other losses. To eliminate problems is a joint responsibility between operations, maintenance and engineering.
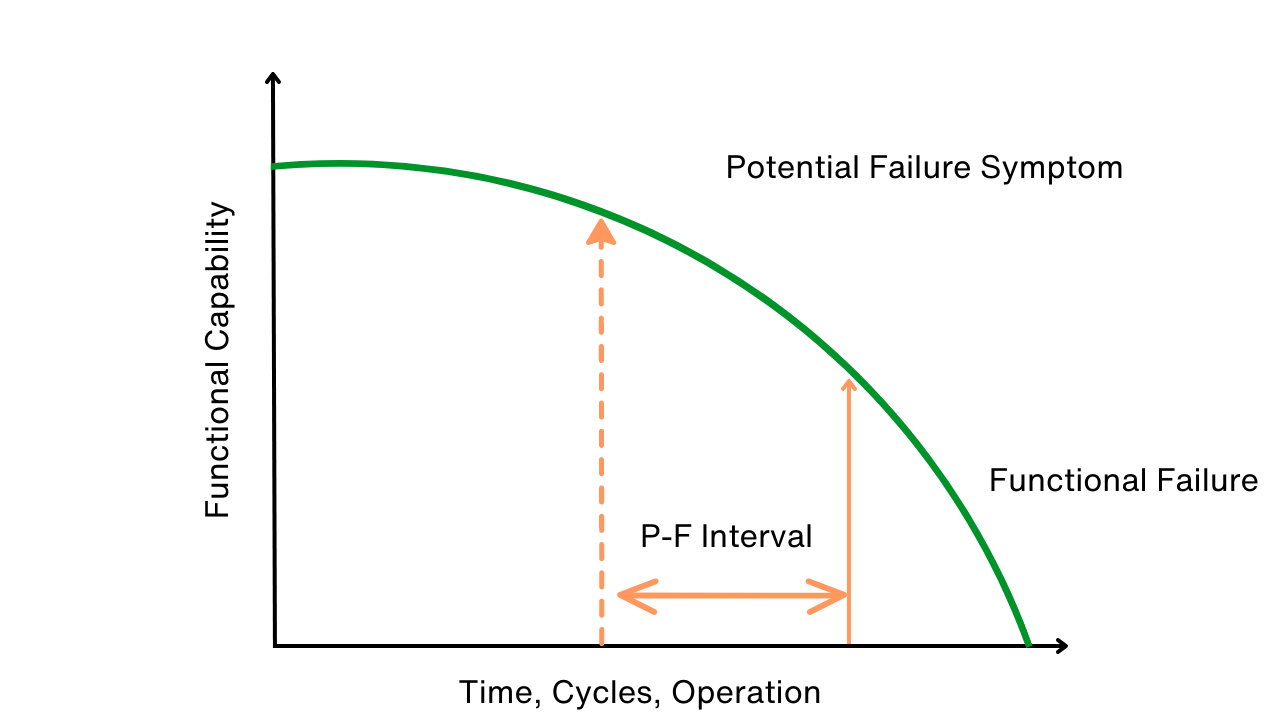
The potential-to-functional failure interval (P-F interval) is one of the most important concepts when it comes to performing Reliability-Centered Maintenance (RCM). Remarkably, the P-F interval is also one of the most misunderstood RCM concepts. The failure mode analysis becomes even more complicated when you are dealing with several P-F intervals for one failure mode. This paper will help clarify the P-F interval and the decision-making process when dealing with multiple P-F intervals.
The potential-to-functional failure interval (P-F interval) is one of the most important concepts when it comes to performing Reliability-Centered Maintenance (RCM). Remarkably, the P-F interval is also one of the most misunderstood RCM concepts. The failure mode analysis becomes even more complicated when you are dealing with several P-F intervals for one failure mode. This paper will help clarify the P-F interval and the decision-making process when dealing with multiple P-F intervals.
As many of us strive to improve the reliability of our plants, several comments bemoan how challenging that is to do in an era of continuous deep cost cutting. They say that in their operation, maintenance is seen as a cost, and is one of the first things to arbitrarily cut. Some think their operations have cut too far! What they seek is a way to justify a strong maintenance capability. I submit that one approach is to speak of maintenance as an “investment in capacity.” Use the language that plant managers, controllers and senior management understands: capital investment and return on investment (ROI).
As many of us strive to improve the reliability of our plants, several comments bemoan how challenging that is to do in an era of continuous deep cost cutting. They say that in their operation, maintenance is seen as a cost, and is one of the first things to arbitrarily cut. Some think their operations have cut too far! What they seek is a way to justify a strong maintenance capability. I submit that one approach is to speak of maintenance as an “investment in capacity.” Use the language that plant managers, controllers and senior management understands: capital investment and return on investment (ROI).