How Service Parts Planning Impacts Machine Uptime
Carl Fransman, Baxter Planning

Predictive maintenance (PdM) is a very hot topic, and rightly so. Holding the promise of cutting down costly unplanned maintenance events, it’s one of those areas where the hopes of saving a lot of money are very real. Parts Planning can play a large role in this effort.
Many domains influence the ultimate performance of any PdM exercise. Some are very hot, such as the Internet of Things (IoT), also denominated as machine to machine (M2M) or Industry 4.0, which allows for the gathering of system data. But, be careful not to confine system data to data pertaining to the machine you’re trying to monitor. Rather, be sure to include the “extended machine,” which could hold data as to the environment (e.g., weather, but in the case of moving equipment also geographic information), driver, origin of fuel, etc. In general, the more circumstantial data you can gather, the greater the chance of being able to put together a meaningful PdM setup.
Obviously, successful PdM is largely dependent on the availability of good predictive analytics (PA). A lot has been written on PA, but generally, there are two schools to deploying PA for PdM. One approach tries to analyze the mechanics of what one tries to predict and from there deduct an algorithm that will lead to determining the chance of something failing. The other approach essentially gathers all the data and allows for automated systems to look for elements that allows one to come up with appropriate algorithms. When well designed and deployed, the latter approach has the advantage because it typically yields many more and often better results than the former. The drawbacks are that it requires a lot of computing power and the results are hard to interpret.
If the resulting forecast is difficult to interpret, it means you can’t determine from the prediction why exactly the event is being predicted. This doesn’t mean the prediction is bad. However, there have been instances where, even in situations where predictions were more accurate than 90 percent, operational issues occurred. What’s happening in the field is that when the computer churns out a prediction, it leads to a machine having to be taken down and a part or several parts end up being replaced. After a few interventions, mechanics start asking questions about why they have to replace parts, which may look perfect, even upon a very thorough inspection. Such is the essence of PA: to catch a part with a high risk of causing a failure before the part is actually faulty. In fact, said part may be able to operate quite well on a different machine; it’s just that on this particular piece of equipment, in these circumstances, etc., this part holds a high risk of failure. It’s difficult enough to explain this to scientists, imagine dealing with mechanics in the field who build upon years of practice. It’s hard to change old habits.
Another domain impacted by PdM, but more down to earth and the focus of this article, is parts planning (PP). The importance of parts planning excellence can’t be understated. When it comes to improving machine uptime, this still may be the domain where most progress is within easy reach. These solutions for optimizing service parts inventories have been around for some time now, but companies keep making some common mistakes. Many believe it’s an inventory and supply chain problem and, therefore, can be solved by regular supply chain approaches. However, service parts supply chains are very different from production or distribution supply chains. Demand is very erratic, hard to foresee, often urgent and includes a reverse supply chain in case of repairs. These are just a few elements that set service parts supply chains apart. Thankfully, in recent years, corporate strategists and consultants have started to realize there’s money up for grabs and parts planning projects typically generate double figure returns very quickly.
All these elements impact machine uptime, so how does parts planning fit into the grand scheme of things? Figure 1 illustrates the typical breakdown of the timescale associated with machine failure.
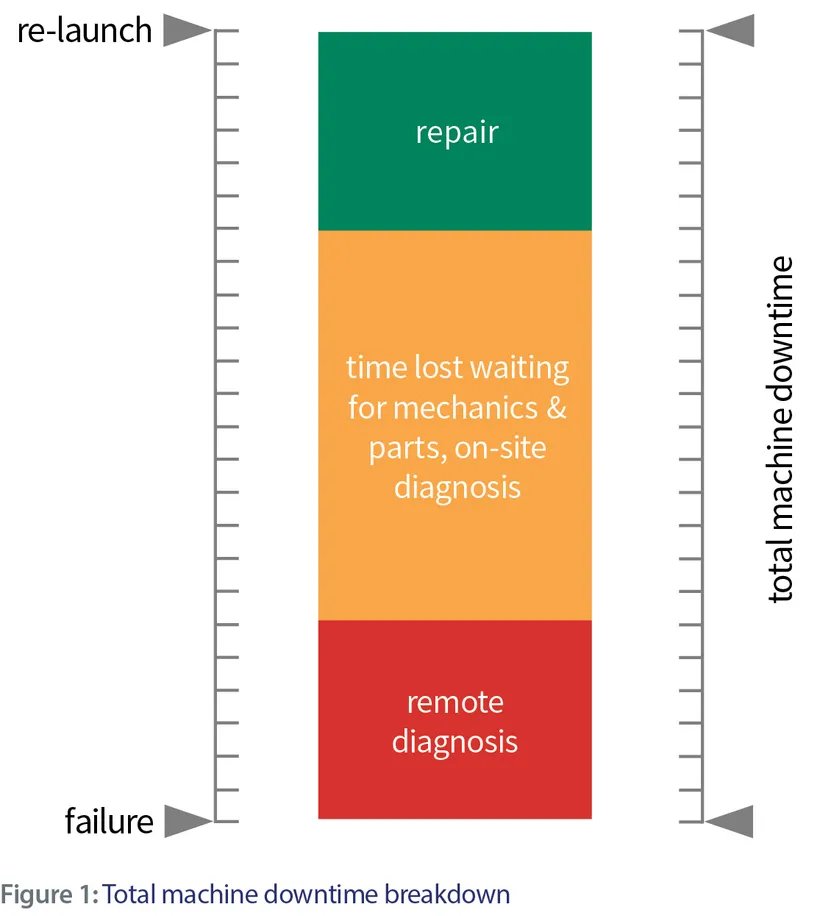
In reality, only a small part of the total downtime is actual repair time. Depending on the industry, the chunk of time spent waiting for mechanics and parts can take up to 90 percent of the total machine downtime. Does this mean you shouldn’t invest in optimizing the repair activity and/or remote diagnostics? Not at all! Actually, better remote diagnostics will avoid having to send out for mechanics more than once (i.e., when the mechanic doesn’t have the required part on hand) and better repair processes should lead to better first-time fix metrics.
However, what Figure 1 really illustrates is that the biggest room for improvement is in the middle section. The simplest solution or Utopia, if you will, would be to have mechanics and parts on-site. It’s not really achievable for all situations, but at least in some cases (e.g., large customer sites, platinum support contracts, etc.), consignment stock is a step in the right direction. The challenge for good consignment stock management is determining the optimal parts mix. Gone are the days of number of machines multiplied by standard parts inventory per machine; one can do much better now.
After consignment stock, van stock is the next closest inventory to the client and, therefore, can have a big impact on the middle section in Figure 1. Ideally, van stock should be managed individually within the network of vans. Each mechanic/van typically serves a geographic area, a set of clients, a type of equipment, etc. However, it’s important to make sure the van stock reflects the addressable installed base. While this may seem trivial, it can be quite a daunting task when overseeing a network of hundreds, let alone thousands, of vans. Below a certain number of vans, the capability to differentiate is often not present, but beyond that threshold, the task becomes too complex and it is often left to the mechanics to partly determine how they stock their vans. This can lead to hidden inefficiencies and capital tied up in inventory that more often than not goes overlooked or is deemed a necessary evil in order to perform. If van stock is part of a company’s daily life, it’s one of those areas that typically can be greatly improved, leading to both positive financial impact and improved repair metrics. It’s not uncommon to see service executives scratching their heads, not knowing what goes wrong, but knowing something does go wrong. Often, van stock is the answer.
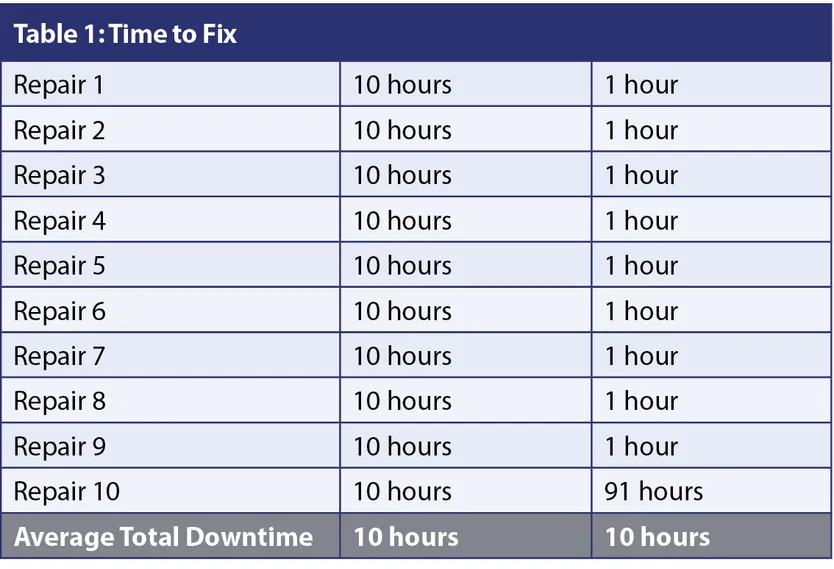
Next are those cases where the part is not on hand, neither on-site nor as part of the van stock. Believe it or not, it’s these cases that separate bad, good and excellent service organizations. Imagine 10 interventions with an average total machine downtime of 10 hours. Taking the two extremes, as shown in Table 1, this could be the result of 10 interventions of 10 hours each (if that’s the time a repair of this sort takes, excellent) or nine repairs of one hour each and one repair of 91 hours.
While this may be an extreme illustration (although ask your service organization, it’s much more common than you may think), it highlights two important points of interest. First, handle metrics with extreme care, especially when looking at averages, as they may hide or disguise situations as something they’re not. Second, in the second case, there’s a clear opportunity for avoiding a potentially very upset client, as well as all the stress this one case will undoubtedly have brought to the service organization. If the repair took so long due to a missing part, chasing the part, expediting it, etc., it is not only stressful, but also often extra expensive.
For this reason, the design, management and deployment of a well performing and adaptive service parts network are crucial elements. This means that, for optimal planning purposes, what’s on hand at the client’s site, van stock, forward stocking locations, distribution centers, repair centers, supplier lead times, etc., should ideally be visible/known at all times. A good parts planning solution and organization will be able to use all this information to determine the optimal part/location mixes.
As the market moves more toward PdM, the importance of parts planning can’t be understated either. There have been PA projects in the area of PdM where predictions were made within a time frame that couldn’t even cover the lead time for parts. What parts planning can do is either highlight the limitations of the system, thus requiring a longer time frame for the predictions, which is not always possible, or determine what is required from the service parts network in order to be able to address the predictions made by the PA system. This poses some ethical questions, as well. Imagine PA determines a 50 percent risk of failure of a critical part on a machine, which may potentially result in bodily harm, and the part is not available. Is the machine taken out of service until the part has been provided or does the manager go for the other 50 percent?
Planning service parts is about handling risk, forecasting whether or not a part may be required is only a small part of the task. What do you do if the forecast for a part’s failure for next month is 90 percent? The failure could happen on the first or the last day of the month, or not at all. The part could be critical or not, expensive or cheap, available at fallback locations or not, etc. Parts planning is about managing and orchestrating all these risks in order to minimize exposure at the lowest possible or set budget. Regular supply chain solutions or spreadsheets can’t cope with this level of sophistication, which is why specific parts planning software has such a big and almost immediate impact.
The importance of good planning is further underlined by the fact that it’s economically unsustainable to hold inventory for every possible spare part. Parts planning, therefore, is an exercise of choosing which part to hold where. Some parts will be held back at the distribution center or central stock, whereas other parts, such as high volume, critical, etc., will be stored at forward stocking locations. Each decision has an impact on the budget and on achieved service levels. For those parts not stocked within the company’s network, ideally, the lead times for obtaining them should be known. Keep in mind there may be a world of difference between promised and actual lead times. Some suppliers may promise lead times of two weeks, which regularly vary up to two months! Lead time variability should be monitored and decisions made as to which lead time will be applied for planning purposes. Longer lead times typically, but not always, command higher internal inventories. Important questions can be then asked, such as: Would you be willing to pay more for shorter and more dependable lead times? If you’re willing to consider the option, do you have the tools that allow you to calculate the global impact of either option?
Quite worryingly, most company executives lack the tools to evaluate the risks they’re facing, such as what it would cost them to cover those risks up to a certain level and what it would cost them in case they’re not covered. When a part is not available, a whole different process is put in motion in order to get the part on-site. For example, people may have to call colleagues handling other stocking locations in order to find out whether they have the part on hand. Regardless of where the part is coming from, it still needs to get shipped or transshipped, or even procured externally. Often, because of the urgency (e.g., a client’s machine is down), the part has to be expedited. More often than not, all these extra costs are not taken into account for parts planning. This is a huge mistake and one of the main reasons why the annual budget is missed by so much. Having the capability to take into account all these factors can lead to a huge competitive advantage.
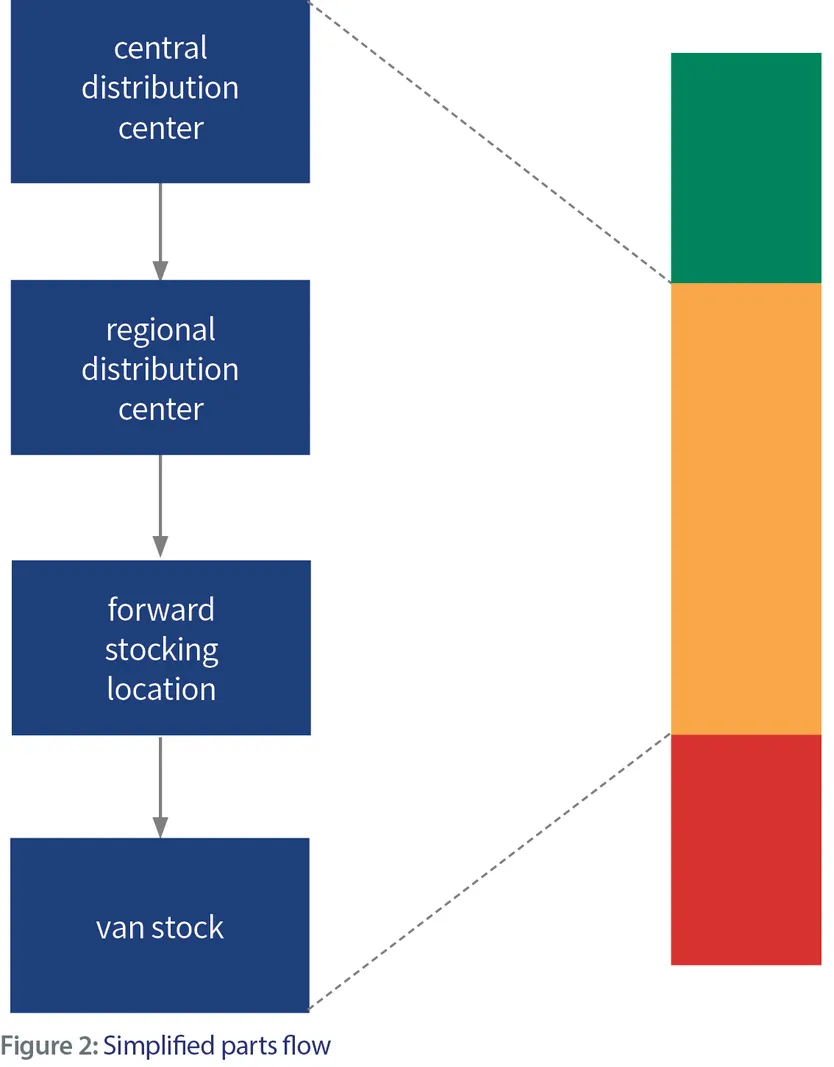
Supported by PA predictions or not, maintenance (predictive or corrective) performance or machine downtime is impacted by parts planning. When a part is stored, a linear and, hopefully, organized flow is set in motion. This results in efficiency and predictability. (Horizontal shipments are possible, as well, for example, between forward stocking locations (FSLs.)Not accounting for horizontal flows, Figure 2 also ignores repair flows, but one easily gets the point. Now, look at the scenario where the part is not internally available.
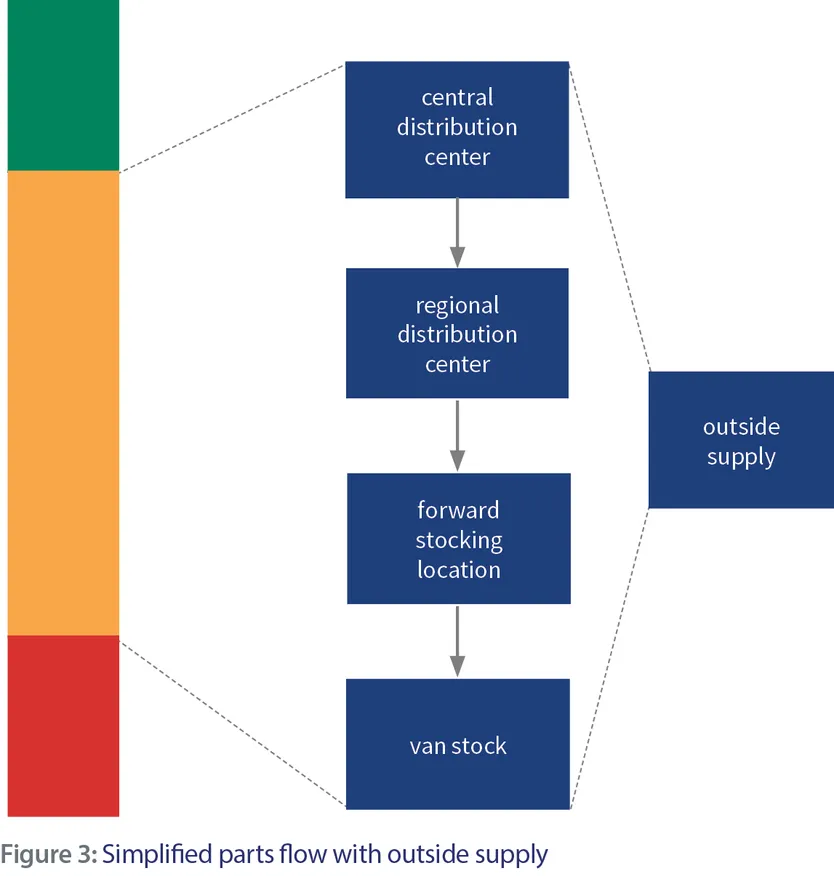
While it is not intended to depict an exact parts flow, Figure 3 illustrates what happens in reality when a part is not available. Depending on the situation and part, it may be procured or inserted at any point in the supply chain. Even when procurement happens centrally, a drop shipment to the FSL or even to the client’s site may be organized. All these possibilities add complexity, unpredictability and length to the whole cycle. Therefore, having the part available in the network has a huge impact on service performance. This also means choosing which parts not to hold is equally crucial, because remember, you can’t have them all. Criticality and the likelihood of needing the part obviously play a key role, but so also does the predictability of the supplier, the ease in which a part can be delivered anywhere in the network, etc. Life is about making choices. If anything, good tools will allow parts planners to present the executive team with several scenarios from which to choose. They can then make a choice based on solid calculations and foresight into cost versus service performance.
Ultimately, increasing machine uptime is the goal: happy customers are faithful and repeat customers.

Carl Fransman
Carl Fransman is Managing Director for EMEA at Baxter Planning. Carl has over 25 years of international management experience in technology and software companies focusing on the aftermarket; spare parts planning, predictive analytics, IoT, etc.
Related Articles

Planned Work Predominance: Contribution to the Bottom Line

The Pitfalls of Planning and Scheduling

Start Designing a Planning and Scheduling Program

Planning and Scheduling: Planners Should Not

Work Order Prioritization

Maintenance Planning and Scheduling Basics


