Weibull Point Process Applied to Repairable Subsystems: An Application to the Cuban Sugar Industry
Ing. Segismundo Mojicar Caballero
In spite of any proactive kind of maintenance, we must face failures that happen in our production assets. These failures have to be treated by a minimal repair, that is, an action that just restore the operability of the failed item to the same condition as before fail. Usually these failures take by surprise production and maintenance people and as repair support is not ready, availability can be seriously affected.
We may ask ourselves: Why do these failures happen even when a preventive (or predictive) maintenance program has been implemented in our industry? Three basic reasons let us discuss about that:
- Generally, all the items of all the systems are not into the preventive program. Failures that can not be forecasted can not be prevented. So random failures are beyond the scope of any preventive action and in complex systems we may find many items that run to failure.
- Maintenance economics limits the maintenance inherent reliability, so we must deal with a probability of failure. If a preventive program of maintenance ensures an item reliability of 95%, we are accepting the risk of 5% of failure probability.
- The preventive maintenance program fails. Sometimes maintenance does not complain possible changes in production rates or the incoming of new production technologies. As the number of failures that should be avoided by the preventive maintenance increases, the effectiveness of the preventive program becomes worse and it has to be improved.
If we want save availability (for example, in a JIT production process) minimal repairs must be avoided, that is, surprising failure events must be reduced to the minimum.
Cuban sugar industry operates continuously during few month per year and the highest technical availability is required as in any other JIT process. Between successive seasons (time that the industry operates) there is a general repair, that is an action that restores the systems to a mean level of reliability similar at the beginning of each season. Under these conditions we can implement the following method for failure analysis:

Let’s suppose that we have recorded the time when each failure of a repairable subsystem has happened during a season. The arrangement of these failures (black points in Figure 1) along the time axis is called a stochastical realization of failure events.
The position of each failure along the time axis is purely random. The preventive (routine) maintenance takes place in fixed intervals (yellow points in Figure 1). In order to achieve such a representation we have assumed that non-operative time in maintenance and minimal repairs (due to failures) is negligible related to the time in operation.
Estimating reliability from a sample of stochastical process realizations.
Just a realization is not enough to make statistical inferences about the failures that happen in a season. We need a sample composed of several of such realizations.
A sample of realizations may be describe by three parameters:
Z: number of realizations in the sample.
R: indicate the type of subsystem (repairable or non-repairable subsystem).
T: time when observation of all the realizations is stopped.
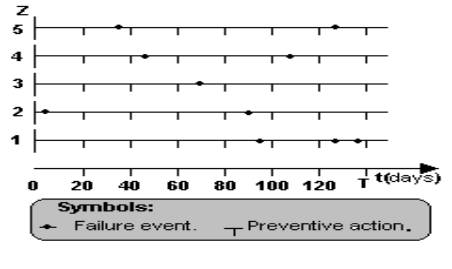
Figure 2. Sample of Z=5 realizations (seasons) observed until T=140 days in a repairable subsystem.
As a general repair between seasons lets us assume that realizations are independent one to each other, we can estimate an average number of failure function:
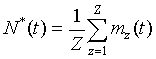
where mz(t) is the total number of failure events that can be counted in all the realizations till time t.
Then, N*(t) is a cumulative function. For t = 0, N*(t) = 0 and always it will show an increasingly trend (positive slope).
| t | 0 | 20 | 40 | 60 | 80 | 100 | 120 | 140 |
| N*(t) | 0 | 0.2 | 0.4 | 0.6 | 0.8 | 1.2 | 1.4 | 2 |
Table 1 shows the values that take the N*(t) function for the sample shown in Figure 2.
Fitting a mathematical model.
The N*(t) function can be fitted to a mathematical model using a non-linear regression procedure. In this case we use a Weibull model, where the expected number of failures is given by:
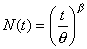
where b is the shape parameter and q is the average time per season when the first failure happens.
| t | 0 | 20 | 40 | 60 | 80 | 100 | 120 | 140 |
| N(t) | 0 | 0.13 | 0.33 | 0.58 | 0.86 | 1.18 | 1.52 | 1.89 |
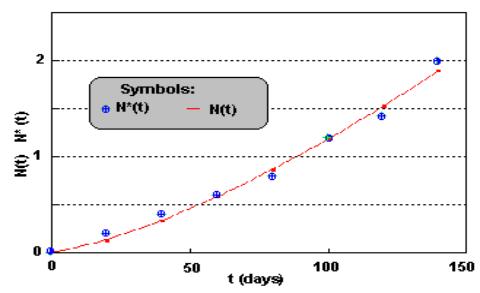
Table 2 shows the values of the fitted function N(t) for the example we are carrying out. The estimated parameters are: b =1.39 and q =88.5 days. Figure 3 shows both functions N*(t) and N(t). The goodness of the fit is measured by R2 = 0.98.
Discussion:
The function N(t) may show different outcomes. We are going to delve in the possible values of the shape parameter.
If b = 1, the N(t) function is a linear function with a constant slope . It means that failures, in spite of the preventive maintenance program, happen randomly.
If b < 1, the N(t) function slope becomes less abrupt as time runs. In this case, failures happen mostly at the beginning of the observation period and they are due to repair errors (if the start of each realization is defined by the fulfillment of a general repair as in our study in the Sugar Industry).
If b > 1, the N(t) function slope becomes more abrupt as time runs. In this case failures are time dependent and it points that preventive actions are not able to avoid the evolution of these failures.
From the N(t) function other important reliability features can be derived, as it is shown in Table 3.
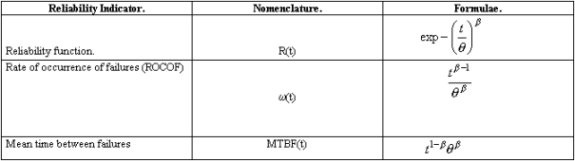
The procedure, that for simplicity we called Weibull Point Process (WPP), leads to important conclusions about the Maintenance Inherent Reliability (MIR) and lets us implement new mathematical approaches in order to control maintenance effectiveness and optimize its variables. In next articles we will discuss these approaches.
Related Articles

Troubleshooting Mechanical Seals | Coking | Part 7

Bearing Repair: An Alternative to Replacement

Keys for Effective Troubleshooting

Troubleshooting Paper Machine Problems Through Thermal Imaging
Troubleshooting Mechanical Seals | Scoring | Part 5

Troubleshooting Premature Bearing Failure


